💡 Hosting tip: For self-hosted setups, Contabo VPS for self-hosted AI agents offers high-performance VPS at excellent value.
Alibaba’s Qwen team just released the Qwen 3.5 Small Model Series — four compact, powerful models (0.8B, 2B, 4B, and 9B) built on the same Qwen3.5 foundation as their larger counterparts. The pitch: native multimodal, improved architecture, scaled reinforcement learning, and serious performance for their size class.
Four Models, One Family
The Qwen 3.5 series drops four sizes today, each targeting a different use case:
- Qwen3.5-0.8B — Tiny and fast. Built for edge devices, on-device inference, and latency-critical applications where cloud round-trips aren’t acceptable.
- Qwen3.5-2B — Still small, but meaningfully more capable. Fits comfortably in memory on consumer hardware and embedded systems.
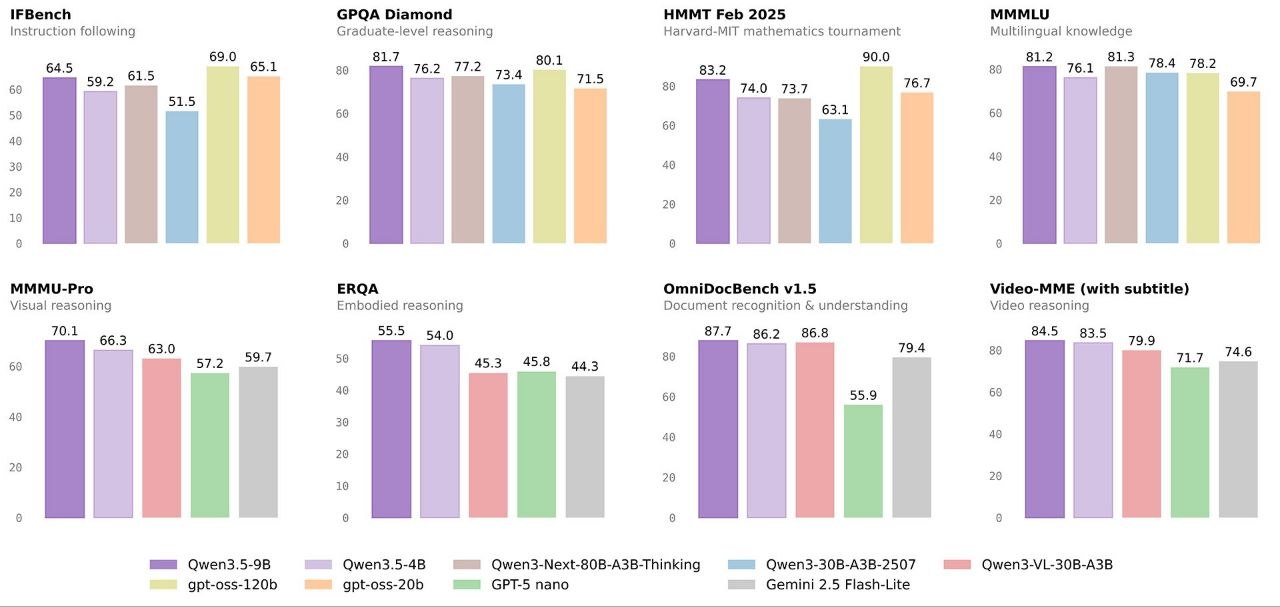
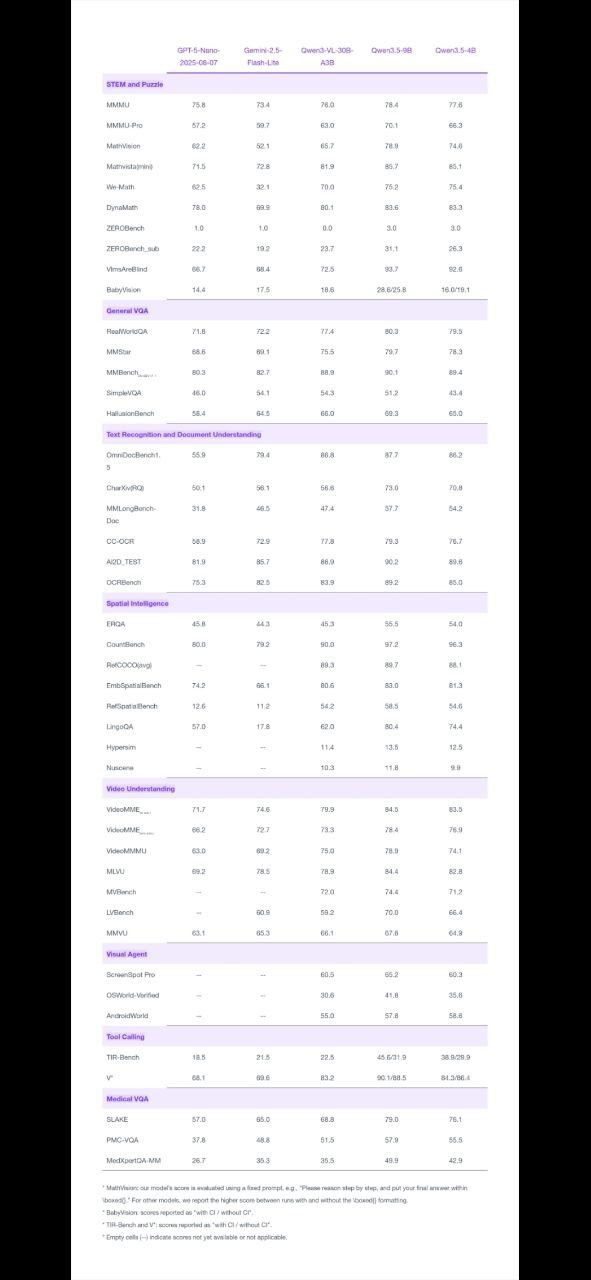
- Qwen3.5-4B — The most interesting size in the lineup. Alibaba calls it “a surprisingly strong multimodal base for lightweight agents” — a big claim for a 4B model. If it delivers on multimodal tasks, this becomes a go-to for developers building on-device AI agents.
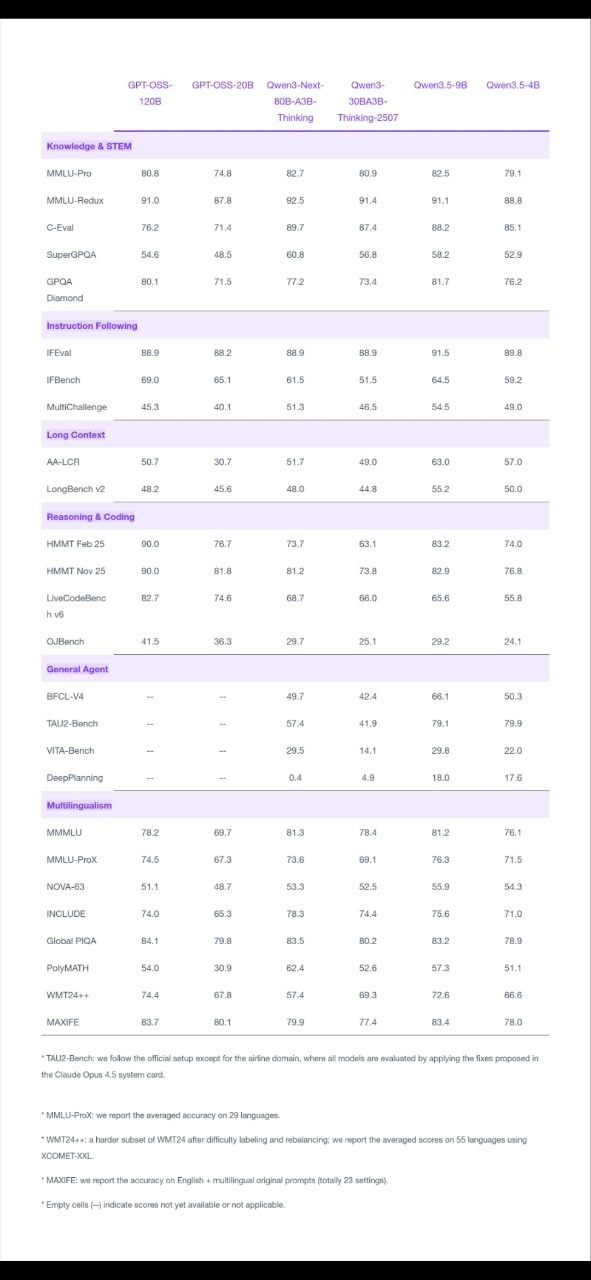
- Qwen3.5-9B — Compact by today’s frontier standards, but Alibaba says it’s “already closing the gap with much larger models.” A 9B that competes with 70B+ outputs would be a genuine breakthrough.
What “Native Multimodal” Means Here
All four models are described as native multimodal — meaning multimodal understanding is baked into the architecture from the start, not retrofitted via adapters or separate vision towers. This avoids the common trap of “multimodal” small models that are really language models with a bolt-on image encoder that degrades text performance.
The 4B model is being positioned as a capable base for lightweight AI agents that can process both text and images without requiring a large model backend — think a phone app that reads a document photo and answers questions about it, all running locally.
Scaled RL: The Secret Ingredient
The Qwen team specifically calls out scaled reinforcement learning as a key differentiator. This aligns with the broader industry shift — following DeepSeek R1 and OpenAI’s o-series — of using RL to dramatically improve reasoning quality without simply scaling parameter count. For small models especially, RL training can extract far more capability from limited compute.
Base Models Released Too
Alibaba is also releasing the Base models (pre-instruction-tuning) for all four sizes. This matters for researchers and developers who want to fine-tune on custom data without fighting RLHF preferences — crucial for domain-specific applications in medicine, law, code, or any specialized vertical.
Why Small Models Are Having a Moment
The release arrives at a moment when the industry is re-evaluating the race to scale. GPT-5 and Gemini Ultra get the headlines, but real deployment volume — in apps, devices, and enterprise edge infrastructure — is driven by models that are fast, cheap, and small enough to run anywhere. A capable 4B multimodal agent that runs on a phone changes what’s possible for bootstrapped products and resource-constrained research.
Where to Get Them
- Hugging Face: huggingface.co/collections/Qwen/qwen35
- ModelScope: modelscope.cn/collections/Qwen/Qwen35
Curious how Qwen 3.5 stacks up against Phi-4, Gemma 3, and Llama 3.2? Check our free AI Model Comparison tool →
This article was produced with the assistance of AI tools and reviewed by the AIStackDigest editorial team.